Decision Tree
🌳 What Is It?
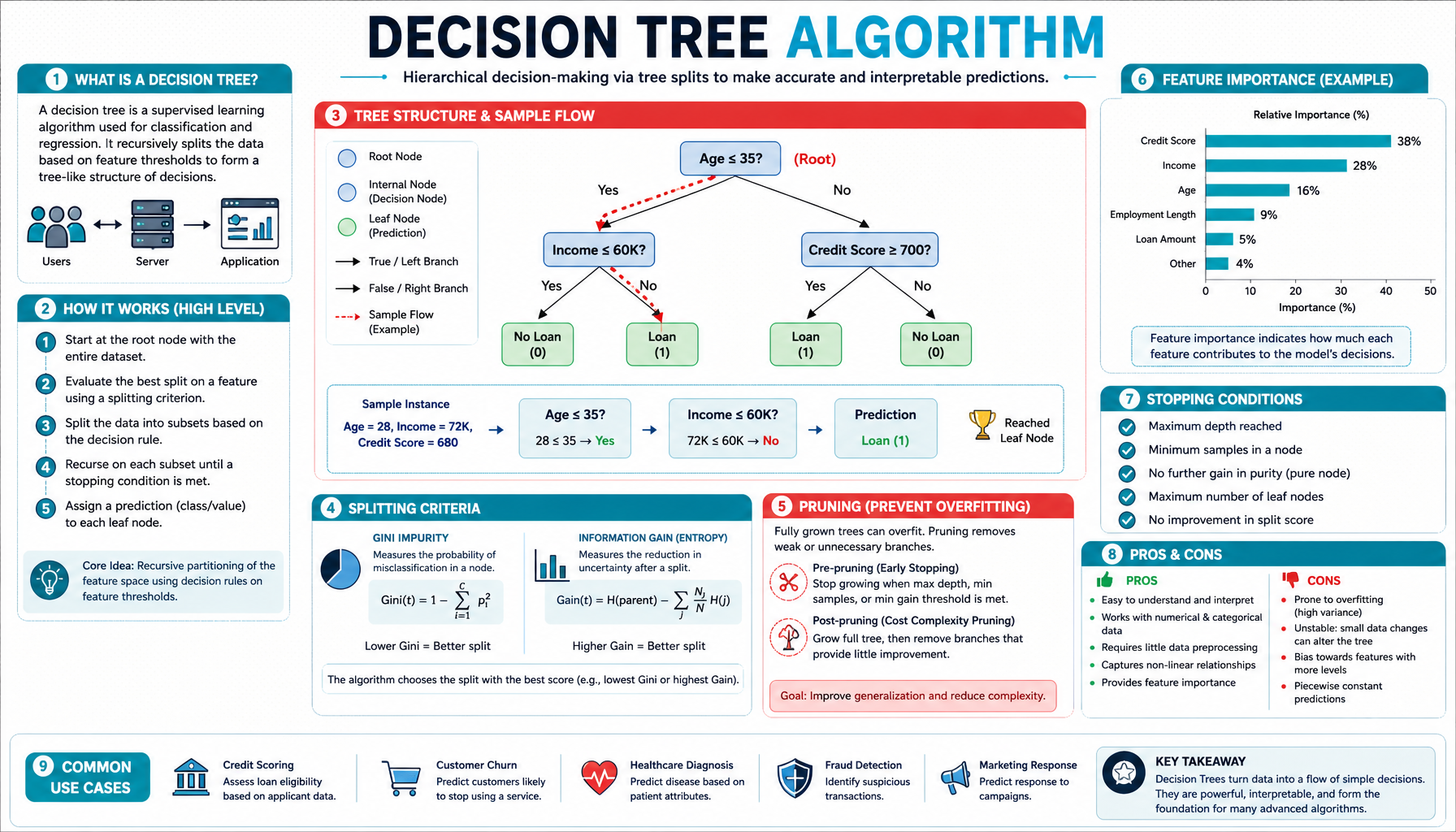
A Decision Tree is like playing "20 Questions" with your data. It makes decisions using a flowchart of if-then rules, where each node asks a question about a feature.
🎯
Group 1
Group 2
🎉
🎊
🎉
🔢 The Math Behind It
1. Entropy (Disorder Measure)
What it means: How mixed up is this group?
- H = 0 → Perfectly pure (all same class) 🎯
- H = 1 → Maximum chaos (equal split) 🌪️
2. Information Gain
What it means: How much uncertainty did this split remove?
The algorithm picks the split with the highest information gain!
3. Gini Impurity (Alternative)
What it means: Probability of incorrect classification
- ✅ Faster to compute than entropy
- ✅ Similar results in practice
🎯 Key Concepts
1. Tree Depth vs Overfitting
High bias, low variance
Risk: Underfit (too simple)
Low bias, high variance
Risk: Overfit (memorizes noise)
Sweet spot: Use cross-validation to find optimal max_depth
2. Pruning Strategies
- Pre-pruning: Stop early (max_depth, min_samples_split)
- Post-pruning: Build full tree, then cut back weak branches
- Goal: Reduce overfitting, improve generalization
3. Feature Importance
Measures how much each feature reduces impurity across all splits
📊 When to Use Decision Trees
✅ Great For:
- Interpretability: Easy to explain decisions to non-technical folks
- Mixed data types: Handles numerical + categorical features
- Non-linear relationships: Captures complex patterns automatically
- Feature interactions: Finds interactions without manual engineering
- Quick prototyping: Fast to train and test
❌ Not Ideal For:
- High-dimensional sparse data (text embeddings, images)
- Extrapolation (can't predict outside training range)
- Stable predictions (small data changes = big tree changes)
🆚 Comparison with Other Algorithms
✅ Handles non-linearity
✅ No feature scaling needed
✅ Faster prediction (O(log n))
✅ More interpretable
🛠️ Hyperparameters to Tune
max_depth: Maximum tree depth (controls complexity)min_samples_split: Minimum samples to split nodemin_samples_leaf: Minimum samples at leafmax_features: Features to consider per splitcriterion: "gini" or "entropy"
🎓 Checkpoint Questions
Question 1: What is entropy?
Think before you peek at the answer below...
💡 Answer
Entropy is a measure of disorder/uncertainty in a dataset. 0 = perfectly pure (all same class), higher values = mixed classes. The algorithm uses entropy to decide which splits reduce uncertainty the most.
Question 2: How does a decision tree choose which feature to split on?
💡 Answer
The tree evaluates ALL possible splits, calculates information gain (reduction in entropy/Gini impurity) for each, and picks the split with the highest gain. This maximizes how much we learn from each question.
Question 3: Why do deep trees overfit?
💡 Answer
Deep trees memorize training data noise by creating too-specific rules. They perform great on training data but fail on new data. Pruning (limiting depth) keeps rules general and improves generalization.
🚀 Next Steps
After mastering Decision Trees, you'll learn:
- Algorithm #4: Random Forest — Ensemble of decision trees
- Algorithm #8: Gradient Boosting — Sequential trees correcting errors
✨ Phase 1: Supervised Learning — Algorithm 3 of 7 ✨