Phase 1: Supervised Learning
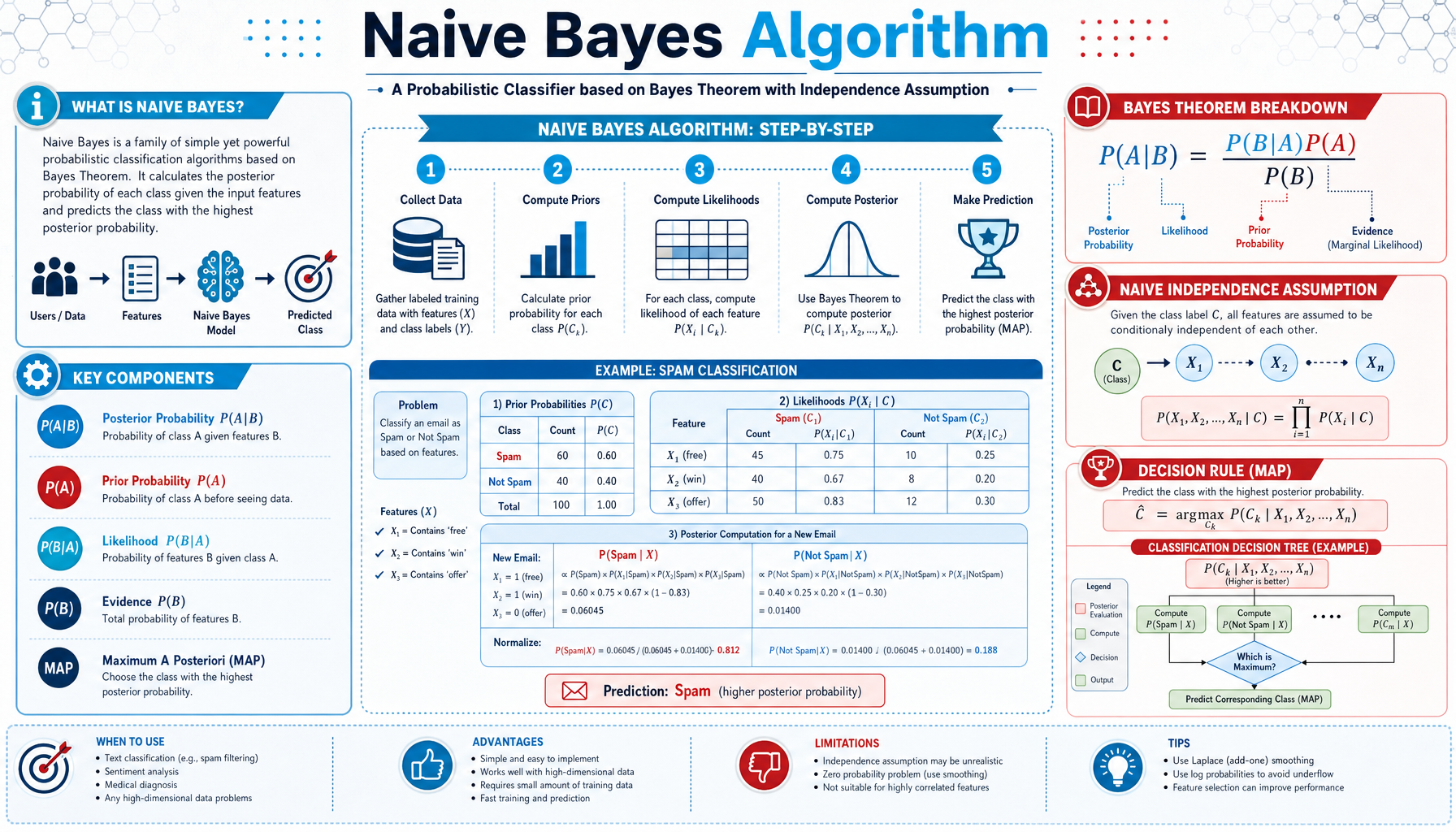
Naive Bayes
Probabilistic Classification
🎯
The Core Idea
Naive Bayes is a probabilistic classifier that uses Bayes' Theorem to predict class membership. Given features, it calculates the probability of each class and chooses the most likely one.
P(Class|Features) =
[P(Features|Class) × P(Class)]
÷ P(Features)
📊 Prior
P(Class)
P(Class)
🔍 Likelihood
P(Features|Class)
P(Features|Class)
📈 Posterior
P(Class|Features)
P(Class|Features)
📐 Evidence
P(Features)
P(Features)
🤔
The "Naive" Assumption
The classifier assumes all features are independent given the class. This simplifies computation dramatically but is rarely true in reality.
Example: In spam detection, it assumes word occurrences are independent (even though "buy" and "now" often appear together in spam).
⚖️ Trade-off: Speed vs Realism
⚙️
How It Works
- Calculate Prior: P(Class) from training data
- Calculate Likelihood: P(Featurei|Class) for each feature
- Apply Bayes' Rule: Multiply prior × all likelihoods
- Predict: Choose class with highest probability
Predicted Class =
argmax [P(Class) × ∏ P(Featurei|Class)]
🔢
Three Variants
📊 Gaussian Naive Bayes
Continuous features (assumes normal distribution)
📝 Multinomial Naive Bayes
Discrete counts (word frequencies in text)
✅ Bernoulli Naive Bayes
Binary features (word present/absent)
💪
Practice Exercises
- Implement spam classifier using Multinomial Naive Bayes
- Compare accuracy with Logistic Regression on same dataset
- Visualize how the independence assumption fails
- Measure prediction speed vs other classifiers
⏰
Checkpoint Questions (2 PM)
Question 1
Write out Bayes' Theorem
What does each term (prior, likelihood, posterior, evidence) represent?
Question 2
Why is the "naive" assumption useful but unrealistic?
What computational benefit do we gain? What reality do we ignore?
Question 3
When would Naive Bayes outperform Logistic Regression?
Consider feature relationships and training data size.
🌍
Real-World Applications
Email Spam Filtering
Sentiment Analysis
Document Categorization
Medical Diagnosis
Real-time Classification